
В предыдущих статьях мы подробно разобрались, как работают два отечественных криптоалгоритма «Кузнечик» и «Магма». Однако с их помощью получится зашифровать весьма скудный кусочек информации (если использовать «Кузнечик», длина этого кусочка составит только лишь 16 байт, а если применять «Магму», то и того меньше — всего 8 байт). Понятно, что нынче в такие объемы ничего втиснуть не получится, и нужно что-то с этим делать.
Что с этим делать, подробно изложено в очередном российском стандарте, который именуется ГОСТ 34.13—2015 «Информационная технология. Криптографическая защита информации. Режимы работы блочных шифров». Этот нормативный документ, так же как и его собратья по криптографическому ремеслу, рожден в Центре защиты информации и специальной связи ФСБ при содействии ОАО «ИнфоТеКС».
Данный стандарт определяет, каким образом зашифровывать и расшифровывать сообщения, размер которых может значительно превышать размер одного 8- или 4-байтного блока.
Всего рассматриваемый стандарт описывает и определяет шесть режимов работы алгоритмов блочного шифрования:
- режим простой замены (ECB, от английского Electronic Codebook);
- режим гаммирования (CTR, от английского Counter);
- режим гаммирования с обратной связью по выходу (OFB, от английского Output Feedback);
- режим простой замены с зацеплением (CBC, от английского Cipher Block Chaining);
- режим гаммирования с обратной связью по шифротексту (CFB, от английского Cipher Feedback);
- режим выработки имитовставки (MAC, от английского Message Authentication Code).
Следует отметить, что стандарт не регламентирует строгое использование в качестве алгоритма блочного шифрования только «Кузнечик» или «Магму», данный алгоритм может быть любым (так же как и размер одного блока), однако в стандарте в качестве примеров рассматриваются блочный шифр с размером блока 8 байт (в этом случае подразумевается «Магма») и блочный шифр с размером блока 16 байт (здесь имеется в виду «Кузнечик»).
Операция дополнения сообщения
Прежде чем непосредственно рассмотреть режимы работы, необходимо познакомиться с одной весьма важной операцией — операцией дополнения сообщения, или паддинга (от английского Padding — набивка, заполнение).
Эта операция применяется при реализации режимов простой замены, простой замены с зацеплением и режима выработки имитовставки. Дело в том, что указанные режимы работают только с сообщениями, длина которых кратна размеру одного блока (напомню, 8 байт для «Магмы» и 16 байт для «Кузнечика»). Для сообщений, длина которых не кратна размеру блока, получающийся остаток необходимо дополнить до размера полного блока.
ГОСТ 34.13—2015 определяет три возможные процедуры дополнения.
Процедура 1
Данная процедура применяется при работе в режиме простой замены или простой замены с зацеплением. Суть процедуры в том, что остаток в сообщении дополняется нулями до размера полного блока.

Использование этой процедуры не позволяет гарантировать однозначное восстановление исходного сообщения из расшифрованного, если неизвестна длина дополнения либо длина исходного сообщения.
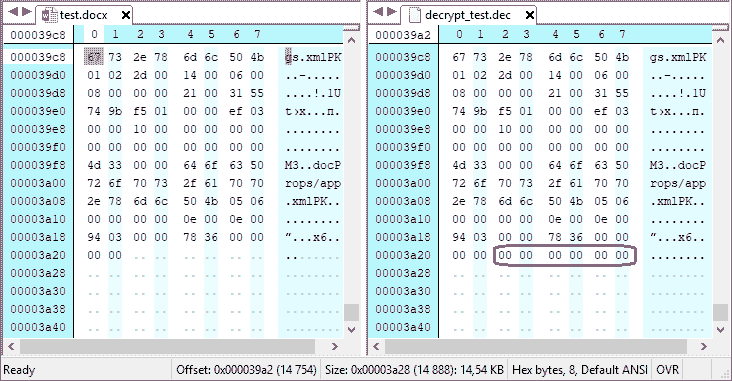
Процедура 2
Особенность этого варианта процедуры дополнения заключается в том, что дополнение выполняется в любом случае, независимо от того, кратна длина сообщения размеру блока или нет. Это позволяет восстанавливать исходное сообщение из расшифрованного без знания дополнительной информации (длины исходного сообщения или длины дополнения).

При реализации этой процедуры возможно два варианта: длина исходного сообщения не кратна размеру блока (то есть в конце сообщения имеется неполный блок) и длина исходного сообщения кратна размеру одного блока.
В первом случае в первый бит остатка пишется единица, а остальное место заполняется нулями до размера полного блока. Во втором к сообщению добавляется целый дополнительный блок, начинающийся с единичного бита, с заполнением остальных разрядов этого дополнительного блока нулями.
Такой вариант дополнения также рекомендован для использования в режиме простой замены или простой замены с зацеплением.
Процедура 3
Эта процедура похожа на первую тем, как она выполняется, и на вторую содержимым этого дополнения. Если длина сообщения кратна размеру блока, то никаких дополнений делать не нужно, в противном случае остаток исходного сообщения дополняется до размера полного блока единичным начальным битом с последующим заполнением нулями.

Процедуру, реализованную в таком варианте, рекомендуется использовать только для режима выработки имитовставки.
Из описанных в стандарте режимов рассмотрим первый.
Режим простой замены (ECB)
Здесь все достаточно просто: весь исходный текст делится на блоки, в случае необходимости производится дополнение последнего блока, далее каждый блок шифруется с применением нужного алгоритма блочного шифрования, и в итоге получившиеся зашифрованные блоки и будут составлять зашифрованное сообщение.

Расшифровывание реализуется в обратном порядке.

Для того чтобы реализовать данный режим, для начала определим несколько базовых функций (в коде мы будем использовать описанные в прошлой статье функции алгоритма блочного шифрования «Магма», хотя ничто не мешает заменить их функциями блочного шифрования для другого алгоритма, например «Кузнечика»).
Определение длины исходного текста
Будем полагать, что исходное сообщение (или исходный текст, подлежащий шифровке) содержится в каком-либо файле и, соответственно, длиной исходного текста будет размер этого файла в байтах. Самый простой способ узнать это выглядит следующим образом:
|
1 2 3 4 5 6 7 8 |
uint64_t get_size_file(FILE *f) { uint64_t size; fseek(f, 0, SEEK_END); size = ftell(f); fseek(f, 0, SEEK_SET); return size; } |
Далее узнаем длину необходимого дополнения.
Определение длины дополнения
Для начала определим такие вот константы (догадаться об их назначении, я думаю, тебе не составит труда):
|
1 2 3 |
#define PAD_MODE_1 0x01 #define PAD_MODE_2 0x02 #define PAD_MODE_3 0x03 |
Функция определения длины дополнения выглядит следующим образом (здесь BLCK_SIZE константа, в которой определен размер блока в байтах (в нашем случае — восемь), size — длина исходного сообщения, pad_mode — вид процедуры дополнения):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#define BLCK_SIZE 8 ... ... uint8_t get_size_pad(uint64_t size, uint8_t pad_mode) { if (pad_mode == PAD_MODE_1) // Если дополнение для процедуры 1 не нужно, возвращаем 0 if ((BLCK_SIZE - (size % BLCK_SIZE)) == BLCK_SIZE) return 0; if (pad_mode == PAD_MODE_3) // Если дополнение для процедуры 3 не нужно, возвращаем 0 if ((BLCK_SIZE - (size % BLCK_SIZE)) == BLCK_SIZE) return 0; // Возвращаем длину дополнения return BLCK_SIZE - (size % BLCK_SIZE); } |
Если последний блок исходного сообщения полный (то есть содержит нужное количество байтов, в зависимости от алгоритма блочного шифрования), то для процедуры 1 и 3 функция возвратит ноль (то есть дополнение не нужно), а для процедуры 2 возвращаемое значение будет равно размеру одного блока исходного сообщения (в нашем случае для алгоритма «Магма» оно будет равно восьми). Если же последний блок исходного сообщения неполный, то возвращаемое значение будет равно числу байтов, которое необходимо для дополнения этого блока исходного сообщения до полного.
Дописывание нужного содержимого в дополнение
На вход данной функции подается указатель на участок памяти, в котором хранится исходное сообщение, длина дополнения, длина самого исходного сообщения и вид процедуры дополнения.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
static void set_padding(uint8_t *in_buf, uint8_t pad_size, uint64_t size, uint8_t pad_mode) { if (pad_size > 0) { if (pad_mode == PAD_MODE_1) // Для процедуры 1 { uint64_t i; for (i = size; i < size + pad_size; i++) // Пишем все нули in_buf[i] = 0x00; } if (pad_mode == PAD_MODE_2) // Для процедуры 2 { // Пишем единичку в первый бит in_buf[size] = 0x80; uint64_t i; for (i = size + 1; i < size + pad_size; i++) // Далее заполняем все остальное нулями in_buf[i] = 0x00; } if (pad_mode == PAD_MODE_3) // Для процедуры 3 { // Пишем единичку в первый бит in_buf[size] = 0x80; uint64_t i; for (i = size + 1; i < size + pad_size; i++) // Далее заполняем все остальное нулями in_buf[i] = 0x00; } } } |
Результатом работы функции будет дополненное исходное сообщение (если выполняются все необходимые условия для дописывания дополнения в конец исходного сообщения), либо исходное сообщение останется без изменений (в том случае, если дополнение не требуется).
Удаляем ключи из памяти
В предыдущих двух статьях мы не очищали то место в памяти, где лежат итерационные ключи шифрования, хотя по всем правилам хорошего тона реализации криптографических алгоритмов это делать необходимо. Для этого напишем простую функцию:
|
1 2 3 4 5 6 |
void GOST_Magma_Destroy_Key() { int i; for (i = 0; i < 32; i++) memset(iter_key[i], 0x00, 4); } |
В нашем случае функция предназначена для работы с «Магмой», для алгоритма «Кузнечик» при необходимости подобную функцию, я думаю, вы сможете написать сами.
Шифруем строку
Поскольку файл с исходным сообщением может быть достаточно большим, то его зашифровывание и расшифровывание будем производить отдельными порциями. Функция получает на вход указатель на очередную порцию исходного сообщения, указатель на буфер для хранения этой очередной порции сообщения в зашифрованном виде, указатель на ключ шифрования и размер очередной порции исходного сообщения.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
void ECB_Encrypt(uint8_t *in_buf, uint8_t *out_buf, uint8_t *key, uint64_t size) { // Определяем количество блоков uint64_t num_blocks = size / BLCK_SIZE; uint8_t internal[BLCK_SIZE]; int i; // Развертываем ключи GOST_Magma_Expand_Key(key); for (i = 0; i < num_blocks; i++) { memcpy(internal, in_buf+i*BLCK_SIZE, BLCK_SIZE); // Шифруем блоки GOST_Magma_Encrypt(internal, internal); memcpy(out_buf + i*BLCK_SIZE, internal, BLCK_SIZE); } // Очищаем итерационные ключи GOST_Magma_Destroy_Key() } |
В данном случае для шифрования отдельного блока используется функция GOST_Magma_Encrypt из предыдущей статьи. Если нужно шифровать блоки алгоритмом «Кузнечик», то вместо нее можно использовать функцию GOST_Kuz_Encrypt из статьи про этот алгоритм (не забудьте вместо функций GOST_Magma_Expand_Key и GOST_Magma_Destroy_Key использовать соответствующие функции для «Кузнечика»).
Расшифровываем строку
Функция аналогична функции зашифровывания строки, за исключением ключевой функции GOST_Magma_Decrypt. С ее помощью производится расшифровывание одного блока сообщения.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
void ECB_Decrypt(uint8_t *in_buf, uint8_t *out_buf, uint8_t *key, uint64_t size) { // Определяем количество блоков uint64_t num_blocks = size / BLCK_SIZE; uint8_t internal[BLCK_SIZE]; int i; // Развертываем ключи GOST_Magma_Expand_Key(key); for (i = 0; i < num_blocks; i++) { memcpy(internal, in_buf + i*BLCK_SIZE, BLCK_SIZE); // Расшифровываем блоки GOST_Magma_Decrypt(internal, internal); memcpy(out_buf + i*BLCK_SIZE, internal, BLCK_SIZE); } // Очищаем итерационные ключи GOST_Magma_Destroy_Key() } |
Так же как и в функции зашифровывания, вместо GOST_Magma_Decrypt в случае необходимости можно использовать GOST_Kuz_Decrypt.
Шифруем файл целиком
Мы уже определились, что работать с файлом исходного сообщения будем отдельными порциями, поэтому необходимо обозначить размер буфера для хранения этой порции. Для этого определим константу, в которую запишем нужное значение (я выбрал размер буфера равным одному килобайту, вы можете при желании определить другой):
|
1 |
#define BUFF_SIZE 1024 |
Функция зашифровывания файла выглядит следующим образом:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
void ECB_Encrypt_File(FILE *src, FILE *dst, uint8_t *key, uint64_t size, uint8_t pad_mode) { // Резервируем место под входной и выходной буфер uint8_t *in_buf = malloc(BUFF_SIZE + BLCK_SIZE); uint8_t *out_buf = malloc(BUFF_SIZE + BLCK_SIZE); while (size) { // Шифруем очередную порцию файла if (size > BUFF_SIZE) { fread(in_buf, 1, BUFF_SIZE, src); ECB_Encrypt(in_buf, out_buf, key, BUFF_SIZE); fwrite(out_buf, 1, BUFF_SIZE, dst); size -= BUFF_SIZE; } // Шифруем последнюю порцию файла else { fread(in_buf, 1, size, src); // Делаем дополнение исходного сообщения set_padding(in_buf, get_size_pad(size, pad_mode), size, pad_mode); ECB_Encrypt(in_buf, out_buf, key, size + get_size_pad(size, pad_mode)); fwrite(out_buf, 1, size + get_size_pad(size, pad_mode), dst); size = 0; } } } |
На вход функции подается указатель на файл с исходным сообщением, указатель на файл, в который будет записано зашифрованное сообщение, указатель на ключ шифрования и вид процедуры дополнения.
При резервировании буфера под очередную порцию исходного сообщения и зашифрованного сообщения мы увеличиваем размер буфера на размер одного блока, чтобы была возможность дополнить исходное сообщение полным блоком при режиме дополнения, определяемом процедурой 2.
Расшифровываем файл
Расшифровываем файл следующей функцией:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
void ECB_Decrypt_File(FILE *src, FILE *dst, uint8_t *key, uint64_t size) { // Резервируем место под входной и выходной буфер uint8_t *in_buf = malloc(BUFF_SIZE); uint8_t *out_buf = malloc(BUFF_SIZE); while (size) { // Шифруем очередную порцию файла if (size > BUFF_SIZE) { fread(in_buf, 1, BUFF_SIZE, src); ECB_Decrypt(in_buf, out_buf, key, BUFF_SIZE); fwrite(out_buf, 1, BUFF_SIZE, dst); size -= BUFF_SIZE; } // Шифруем последнюю порцию файла else { fread(in_buf, 1, size, src); ECB_Decrypt(in_buf, out_buf, key, size); fwrite(out_buf, 1, size, dst); size = 0; } } } |
Как видите, эта функция похожа на функцию зашифровывания файла, только отсутствует все, что связано с дополнением и использованием функции ECB_Decrypt вместо функции ECB_Encrypt.
При использовании функций ECB_Encrypt_File и ECB_Decrypt_File файлы, с которыми будут работать эти функции, необходимо открывать с параметром «rb» для чтения или «wb» для записи (то есть открывать их в режиме двоичных, а не текстовых файлов), например вот так:
|
1 2 3 4 |
... FILE *in_file = fopen("D:/encrypt_test.enc", "rb"); FILE *out_file = fopen("D:/decrypt_test.dec", "wb"); ... |
Режим простой замены достаточно несложен в реализации, однако имеет один весьма существенный недостаток: если мы будем шифровать сообщение, которое содержит в себе одинаковые или повторяющиеся блоки, то на выходе мы тоже получим зашифрованные одинаковые или повторяющиеся блоки. Этот недостаток дает возможность вскрыть структуру исходного сообщения.
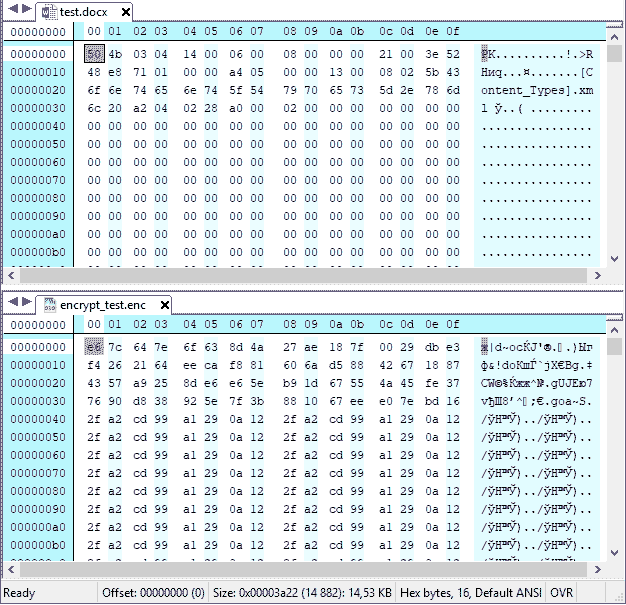
Заключение
Теперь вы знаете, как применять блочные алгоритмы шифрования для работы с сообщениями произвольной длины с использованием режима простой замены. В статье этот режим рассмотрен для алгоритма блочного шифрования «Магма», однако больших сложностей в переработке кода для алгоритма «Кузнечик» нет (все необходимые функции мы написали во второй статье цикла). Этот режим вполне можно применять для шифрования небольших по объему текстовых файлов, в которых отсутствуют какие-либо структурированные части с одинаковыми данными.


