
В сегодняшней статье я покажу, как установить и использовать инструмент для совместного анализа таймлайнов — Timesketch. В качестве исходных данных у нас будет файл Plaso, который мы получили в прошлой статье «Сбор и анализ системных событий с помощью Plaso».
Еще по теме: Форензик кейс взлома серверов под управлением Linux
Timesketch — это проект с открытым кодом, для совместного анализа таймлайнов событий. Под капотом у него размещается крутой восьмицилиндровый elasticsearch (сокращено ES). Основные фишки: масштабируемость, отказоустойчивость и высокая скорость при поиске среди миллионов событий.
Установка Timesketch
Установить можем как релизный вариант, так и development-версию. Второй вариант позволяет вносить свои правки в код, а также добавлять свежие коммиты. Имейте ввиду. Второй вариант поможет нарваться на свежие баги.
В нашем примере будем устанавливать релизную версию на виртуальную машину с Ubuntu и накинем сверху Kibana.
Когда имеете дело с проектами elasticsearch, всегда стоит добавлять Kibana. Это поможет разобраться с процессами происходящими внутри базы и поймать нештатные ситуации.
Копипастить команды из официальной инструкции нет имеет смысла, поэтому будем считать, что с установкой Timesketch разобрались. После установки проверим командой:
|
1 |
$ sudo docker ps -a |
При правильной установке, увидим это:

Теперь откроем порт докер‑контейнера ES, чтобы до него могла достучаться Kibana.
|
1 |
$ sudo nano /opt/timesketch/docker-compose.yml |
В раздел elasticsearch добавляем раздел ports с указанием пробрасываемого порта.
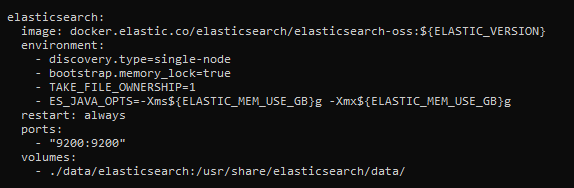
Данный конфиг подходит исключительно для своей тестовой версии ES, доступа к которой нет не у кого. В ES не имеется встроенных механизмов авторизации, и каждый таком образом может запросто получить доступ к базе. Если понадобится подобное решение в продакшене, используйте надстройку X-Pack.
Осталось накатить Kibana. В нашем примере на скрине выше можно увидеть, что в проекте используется elasticsearch-oss:7.10.2, поэтому, и Kibana обязана такой версии. Скачаем и устанавливаем kibana-oss:
|
1 2 3 |
$ wget https://artifacts.elastic.co/downloads/kibana/kibana-oss-7.10.2-linux-x86_64.tar.gz $ tar -xzf kibana-oss-7.10.2-linux-x86_64.tar.gz $ cd kibana-7.10.2-linux-x86_64 |
Исправим конфиг, чтобы достучаться до интерфейса «Кибаны»:
|
1 |
$ nano config/kibana.yml |
Для этого надо раскоментировать параметр server.host и указать IP-адрес виртуальной машины. Запускаем Kibana и проверяем, что все успешно стартануло.
|
1 |
$ /bin/kibana |
Теперь создадим пользователей — и можно залогинится в систему.
|
1 |
$ sudo docker-compose exec timesketch-web tsctl add_user --username user1 |

Использование Timesketch
Для начала создаем новый скетч (кнопка New investigation) и заливаем в него данные, которые сгенерировали в предыдуший раз (кнопка Upload timeline). В нашем примере было создано два скетча. После недолго ожидания заглянем в Kibana, и в разделе dev tools выполним команду:
|
1 |
GET /_cat/indicies?v |

Как видно, для каждого скетча в ES создается отдельный индекс, в который попадают события из каждого загруженного файла Plaso, т. е. один и тот же файл Plaso при загрузке его в разные скетчи будет обрабатываться повторно.
Посмотрим, как данные маппятся, чтобы понимать, как потом эффективно с ними работать
|
1 |
GET /9024dbca65494d1da2dc4758b169f1d9/_mapping |
Все текстовые данные маппятся по следующей схеме:
|
1 2 3 4 5 6 7 8 9 |
{ "type": "text", "fields" : { "keyword": { "type" : "keyword", "ignore_above" : 256 } } } |
Если вы немного знакомы с ES, то в курсе, что перед вами динамический маппинг. Такая схема используется, потому что разработчикам было лень заморачиваться. Timesketch может грузить абсолютно любые последовательности событий из различных источников, и предусмотреть универсальную схему маппинга с четким названием всех полей не так‑то и просто.
Зато такая схема позволяет осуществлять как полнотекстовый поиск, так и агрегировать и сортировать данные по каждому полю в индексе, что несомненно дает много преимуществ, если вы умеете этим пользоваться (и плевать на исчезновение свободных гигабайтов на вашем жестком диске).
Давайте переходить к осмотру пациента. Посмотрим, какие инструменты у нас для этого есть.
Explore
Эта вкладка — основной инструмент для поиска событий в таймлайне, в том числе с применением фильтров и графиков. У вас также есть возможность добавлять комментарии к интересующим событиям, создавать пометки и сохранять view для их дальнейшего использования в Stories.
Поскольку каждый скетч — отдельный индекс в ES, можно не бояться повредить в ходе работы чужие комментарии или пометки в другом скетче. Это крайне важно в многопользовательских forensic-системах. Именно поэтому в данном проекте применяется не самая логичная с виду система хранения данных (с повторной загрузкой и дублированием хранимых данных).
Давайте не будем пока что копаться в отдельных событиях, а попробуем визуально оценить наш скетч. Для этого передвинем ползунок chart в положение «вкл» под строкой с запросом и посмотрим на построенную диаграмму событий.

Самый высокий столбик означает, что в системе в этот момент произошло крайне много событий, что зачастую свидетельствует о чем‑то любопытном с точки зрения форензики. Нажмем на него — в результате автоматически применится временной фильтр и можно будет детальнее посмотреть на происходящие в этот момент процессы.


Любопытно! Мы буквально в два клика сумели обнаружить события из прошлой статьи. Напомню: они свидетельствуют о том, что наш противник с использованием автоматического инструмента обходил содержимое диска в поисках интересных вещей.
Теперь сохраним этот запрос, нажав кнопку Save this search, и попробуем понять, нашел ли злоумышленник то, что искал.
Думаю, вы в курсе, что пользователи любят хранить (или забывают удалить) всякую важную информацию на рабочем столе, в папке загрузок и прочих подобных местах. В большинстве случаев злоумышленники, ввиду нехватки времени, осуществляют сбор личной информации о пользователе в том же порядке. То есть от простых и самых распространенных ситуаций идут к сложным и редким.
Теперь добавим к существующему временному фильтру минут 5 сверху (хакеру нужно время, чтобы понять, какой файл утащить с компа), а в поисковой строке напишем запрос:
|
1 |
*Documents* OR *Desktop* OR *Downloads* |
На выходе имеем 1266 событий. Глянем, какая подробная информация о выбранных событиях нам доступна.


Одно из ключевых полей каждого события — parser, оно позволяет понять, откуда Plaso получил его. Удобно бывает отфильтровать в выводе тип событий, нажав на кнопку в первом или втором столбце (по смыслу это применение логических И или НЕ в запросе).
Давайте это применим. Поскольку мы примерно представляем алгоритм поиска интересующих файлов на файловой системе (конкретно это: проход по всем каталогам и подкаталогам, получение списка файлов из них, получение доступа к интересующим файлам), мы можем попытаться понять, были ли какие‑то файлы похищены. Выберем из событий любое с параметром parser:filestat и file_entry_type:directory и добавим их в фильтр с параметрами AND и NOT.
Это будет эквивалентно такому запросу:
|
1 |
(*Documents* OR *Desktop* OR *Downloads*) AND parser:filestat AND NOT file_entry_type:directory |

Вуаля! Перед нами 17 событий, среди которых доступ к файлу с паролями пользователя my_passwords.rtf. Можно отправлять пользователя менять все пароли от всех сервисов.
Собранные нами события не имеют никакого отношения к журналам, которые были старательно зачищены командой clearevиз Meterpreter.
В прошлый раз наводку на инцидент нам дал сам пользователь. А теперь мы без подсказки «звонок другу» попытаемся понять, какое непотребство привело к тому, что злоумышленнику открылись двери к паролям пользователя. Для этого в Plaso есть потрясающе полезный парсер prefetch и соответствующий тип данных:
data_type:windows:prefetch:execution
Prefetcher — один из компонентов Windows, предназначенный для оптимизации запуска исполняемых файлов в системе. Для своей работы он создает специальные структуры данных, которые хранит на диске в каталоге Windows\Prefetch. Наравне с анализом логов, файлы prefectch — кладезь информации для компьютерного криминалиста.
Используем этот тип данных в качестве фильтра, а также для первого осмотра исключим из вывода все исполняемые файлы, которые были запущены из каталогов Windows или Program Files. Запрос в данном случае будет выглядеть так:
|
1 |
data_type:windows:prefetch:execution AND NOT path_hints: "WINDOWS" OR NOT path_hints: "Program" |

Одним простым запросом мы в первых же 25 событиях увидели, что из папки Downloads запускался файл с заманчивым названием.
Aggregate
Посмотрим теперь, как так получилось, что несмотря на попытки зачистить информацию о своих действиях, факты все равно вышли наружу. Для этого перейдем во вкладку Aggregate.
Эта вкладка позволяет группировать интересующие вас события, выводить статистику по примененным фильтрам, строить таблицы и графики, а также находить аномалии в группах событий.
Попробуем оценить, какие события происходили в момент, когда был запущен поиск интересующего файла на файловой системе. Для этого выберем поле parser в качестве группирующего и зададим определенные ранее временные рамки.
 Нажимаем на кнопку, получаем результат.
Нажимаем на кнопку, получаем результат.

Действительно, как мы и предполагали, основная масса относится к событиям, добытым из парсера filestat, то есть это события файловой системы, которые clearev зачищать не умеет. Парсер winreg/amcache остался в данном случае не у дел по причине того, что образы были сняты в разное время. Соответственно, события, которые попадают в amcache.hve, просто перетерлись более свежими. Так что проблема в данном случае скорее в чистоте эксперимента, чем в каких‑то чудо‑возможностях Meterpreter.
Примечательно, что по графикам, которые строятся в текущей вкладке, можно кликать. Когда вы нажимаете на интересующий вас элемент, открывается вкладка Overview, где будут сразу применены необходимые фильтры.
Также графики, которые вы построили и которые заслуживают дальнейшего внимания, можно сохранить для использования в Stories, нажав соответствующую кнопку.
Analyze
Отдельно стоит обратить внимание на вкладку Analyze. Чего греха таить, на самом деле большинство кейсов начинается именно с нее. Timesketch поставляется с большим набором встроенных анализаторов, использование которых позволяет автоматически отметить тегами разные группы событий, которые бравыми бойцами DFIR уже давно запротоколированы как явно свидетельствующие о чем‑то необычном, возможно требующем внимания. Все анализаторы находятся в каталоге /timesketch/lib/analyzers и написаны на Python. Сразу после установки вам доступны анализаторы для:
- работы с поисковыми запросами, сделанными в браузере (причем будет сразу видно, где, что и когда искал пользователь);
- выявления активности, не попадающей в обычные часы работы пользователя за компом (которые тоже определяется статистически);
- связывания последовательности событий (например, могут быть связаны скачанные и запущенные исполняемые файлы, скопированные и заархивированные для эксфильтрации файлы и тому подобное);
- поиска следов попыток зачистить логи;
- анализа подключений по RDP;
- выявления попыток брутфорса паролей.
Результаты работы анализаторов вы можете найти на вкладке Overview. Для этого необходимо нажать три вертикальные точки на интересующем вас таймлайне и выбрать из выпадающего списка Analyzer.
Если понадобится, вы и сами можете создать новый анализатор. Для проверки его работоспособности в каталоге test_tools есть скрипт analyzer_run.py, которому для работы необходимо подать на вход файл CSV с событиями и ваш hello_world_analyzer.py.
Посмотрим, чем поможет в нашем кейсе встроенный анализатор Chain linked events. Для этого выберем наш таймлайн, возьмем соответствующий анализатор и запустим процесс.


Для просмотра всех связанных событий в строке поиска необходимо набрать запрос:
|
1 |
chains:* |
Немного прокрутим ответ и наткнемся на скачанный и запущенный нерадивым пользователем исполняемый файл.

У каждой цепочки событий есть собственный идентификатор, который хранится в ES в поле chains — соответственно, можно искать необходимые цепочки по этим идентификаторам.
Stories
Вкладка Stories позволяет вам и вашим коллегам описывать наблюдаемые явления. Собранная совместными усилиями информация будет взаимодополняющей, при необходимости можно вставлять сохраненные запросы, построенные графики и делать все это с использованием разметки Markdown. Некоторые анализаторы автоматически формируют истории по результатам работы.
По сути, Stories — это готовые фрагменты будущего отчета по результатам анализа таймлайна.
Выводы
Мы с вами познакомились с весьма крутым инструментом, который позволяет превратить скучный анализ файлов CSV в детективное расследование. В следующей статье мы рассмотрим новую технологию Sigma, поддержка которой буквально на днях появилась в Timesketch, научимся писать для нее правила и попробуем, как в анекдоте, «заставить всю эту хрень взлететь».
Еще по теме: Анализ дампа памяти в Volatility



