
Мы уже рассказывали про Телеграм-боты для пробива. Сегодня продолжим говорить про телегу и рассмотрим еще одну популярную тему — парсинг телеграм каналов и чатов.
Еще по теме: Угон Телеграм и как от этого защититься
Последнее время, на всяких компьютерных форумах и сайтах часто поднимают вопрос парсинга чатов и каналов Телеграм. Некоторые пытаются впарить свои сервисы, которые как правило еще то разводилово. Другие, делая умный, вид пытаются чему-то научить. Непорядок подумал я посмотрев на это дело и решил самостоятельно разобраться.
Парсинг телеграм каналов и чатов
В данной статье я постараюсь понятным языком (даже для далеких от программирования пользователей) рассказать, как парсить Телеграм, что можно сделать, а что нельзя и насколько это трудоемко. Заранее предупреждаю. Я не буду выкладывать готовые исходники, но покажу примеры для наглядности.
Всем известно, что в телеге существуют чаты и каналы, где иногда кучкуются большое количество пользователей. Стоит иметь список юзеров, например для рассылки или приглашений.
Как правило под словом «парсинг» в контексте Telegram подразумевается получение списка пользователей чата или канала. Но иногда, еще и получение списка сообщений.
Кстати, если вас интересует деанон пользователя Телеграм, очень рекомендую прочитать статью «Как узнать информацию о пользователе Telegram».
Парсинг телеграм каналов
Канал — это площадка в Телеграм, где подписчикам разрешается только читать сообщения создателя канала. Писать коментарии юзеры не могут, за исключением тех случаев, когда к каналу Telegram привязан чат для комментариев. Тогда у пользователей появляется возможность комментировать сообщения канала.
Вы можете получить список подписчиков канала без привязанного к нему чата с комментариями, только если это ваш канал и у него менее 200 пользотелей. Если какое-то из этих условий не выполняется, парсинг Телеграм реализовать не получится и никто не сможет его провести, что бы вам там ни обещали. Может быть, в ближайщем будущем появятся новые способы, но на даннй момент рабочих способов не существует.
Если к каналу привязан чат с комментариями, тогда спарсить пользователей телеги вы сможете точно так же, как в случае с каким-ниобудь чатом.
Список сообщений на канале можно получить двумя способами: программно, через API Telegram и ручками, экспортом списка сообщений с помощью клиента.
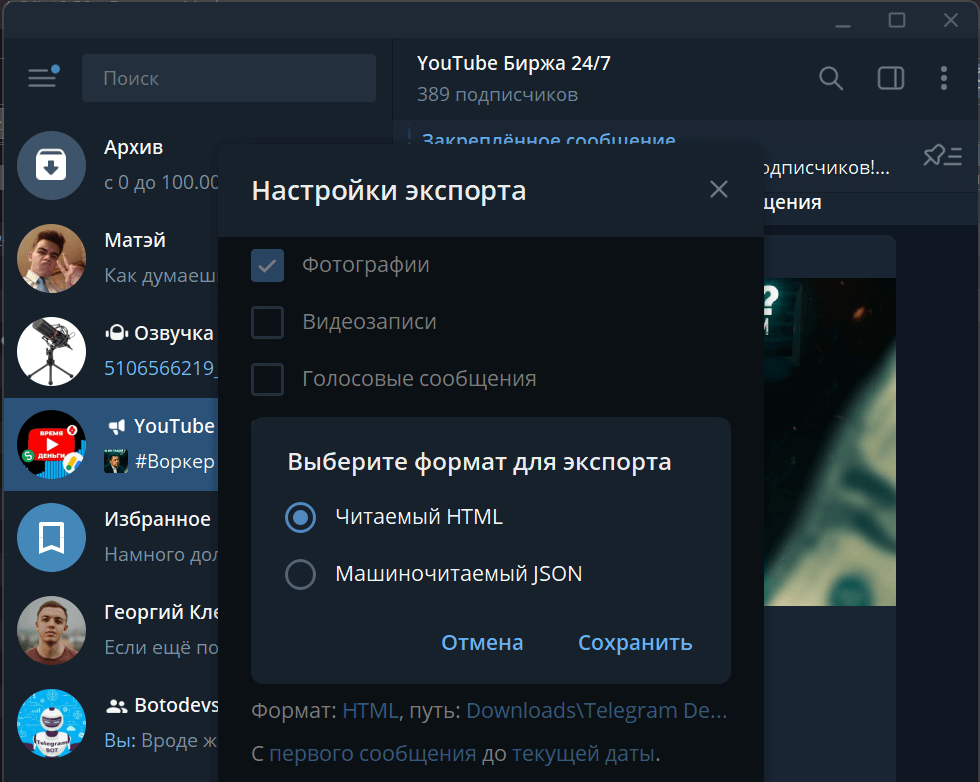
Для этого в меню чата выбираем пункт «Экспорт».
После этого выбираем формат для экспорта и жмем «Сохранить».
Парсинг телеграм чатов
С чатами гораздо интереснее. Вручную вытащить список юзеров через стандартный клиент не получится, разве что сидеть с блокнотом и ручкой и выписывать всю интересующую информацию. Способ не очень, так что придется посмотреть в сторону родного API Телеграм или, если хотите упростить себе жизнь, на какую‑нибудь библиотеку, например Telethon.
В Telethon есть функция GetParticipantsRequest, которая получает на вход некую сущность (entity), а на выходе выдает список пользователей.
Итак, попробуем скормить ей какой‑нибудь чат.
|
1 2 3 4 5 6 7 8 |
async def test1(client): chat_id = 'https://t.me/kakoy-to-chat' chat_entity = await client.get_entity(chat_id) participants = await client(GetParticipantsRequest( chat_entity, ChannelParticipantsSearch(''), offset=0, limit=200, hash=0)) for user in participants.users: print(user) return |
И посмотрим, что можно получить с помощью данной функции:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
User(id=306742xxx, is_self=False, contact=False, mutual_contact=False, deleted=False, bot=False, bot_chat_history=False, bot_nochats=False, verified=False, restricted=False, min=False, bot_inline_geo=False, support=False, scam=False, apply_min_photo=True, fake=False, access_hash=669983103xxxxx, first_name='??\u200d>?', last_name=None, username='prosto_user_name', phone=None, photo=UserProfilePhoto(photo_id=13174487829112xxxx, dc_id=2, has_video=False, stripped_thumb=b'\x01\x08\x08\x04\xe0\xaa\xe0\x8f\x9b\x8cQE\x14\x90\xcf'), status=UserStatusRecently(), bot_info_version=None, restriction_reason=[], bot_inline_placeholder=None, lang_code=None) |
Чаще всего требуются поля id, username, first_name и last_name, phone. Кроме того, здесь еще и куча признаков: bot, verified, scam, fake, photo, status и т.д.
Как видите, информация самая разная. Некоторые специалисты по парсингу Telegram при этом умудряются заявлять, что им удалось получить только ID, а юзернеймы с телефонами — за отдельные деньги. Ловко, ничего не скажешь!
Телефоны, конечно, в этом списке будут отображаться только в том случае, если пользователь в настройках не отключил показ телефона всем.
Кстати, иногда предлагают определять еще и пол пользователя. Таких данных Telegram не предоставляет и не имеет. Мне известно только два способа получать эту информацию:
- анализировать юзернеймы и имена, прогонять их по заранее созданной базе и делать, если возможно, какие‑то выводы. Если имя пользователя, например, Карина, Юля или Алёна, можно считать его женщиной;
- скачивать все сообщения из чата для каждого пользователя, вытаскивать оттуда глаголы и смотреть, насколько часто они заканчиваются на букву «а». Логично предположить, что у женщин таких случаев будет гораздо больше, чем у мужчин.
Очевидно, что оба способа не дают никаких гарантий и позволяют определять пол лишь с некоторой вероятностью и к тому же требуют дополнительных усилий.
Внимательно присмотревшись к результату работы GetParticipantsRequest, мы увидим, что независимо от числа участников чата и от параметра limit нам выдают максимум 200 пользователей. Когда в группе меньше 200 участников, этого достаточно, но если их больше, то придется еще поднапрячься.
Мои эксперименты с параметром offset показали, что он нужен, чтобы указывать смещение в списке пользователей. По умолчанию это смещение равно нулю, но если организовать цикл, на каждой итерации которого увеличивать offset, то будет скачиваться по 200 юзеров и можно парсить до бесконечности (ну или пока не закончатся все юзеры). Например, так:
|
1 2 3 4 5 6 7 8 9 10 |
offset = 0 while True: participants = await client(GetParticipantsRequest( channel, ChannelParticipantsSearch(''), offset, limit, hash=0)) if not participants.users: break #... # Тут делаем что-то с юзерами из списка participants.users #... offset += len(participants.users) |
Однако довольно быстро выясняется, что функция GetParticipantsRequest возвращает максимум 10 тысяч пользователей. Как увеличить этот лимит, выяснить пока не удалось. Есть мнение, что это невозможно.
Параметр filter позволяет задать критерии, которым должны соответствовать возвращаемые результаты.
Есть следующие варианты:
- ChannelParticipantsAdmins;
- ChannelParticipantsBanned;
- ChannelParticipantsBots;
- ChannelParticipantsContacts;
- ChannelParticipantsKicked;
- ChannelParticipantsMentions;
- ChannelParticipantsRecent;
- ChannelParticipantsSearch.
Тут уже можно экспериментировать: попробовать получить список всех админов, например, или всех, кто онлайн. Парсить пользователей в онлайне — вообще хорошая идея. Если делать это регулярно, то можно отсеять неактивных участников, которые добавились в группку и забыли о ней.
Нас больше всего должен заинтересовать параметр ChannelParticipantsSearch, позволяющий искать пользователей по юзернейму или его части. Давайте попробуем замутить цикл:
|
1 2 3 4 5 6 7 8 9 |
chat_id = 'https://t.me/stepnru' chat_entity = await client.get_entity(chat_id) keys = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z'] for key in keys: offset = 0 participants = await client(GetParticipantsRequest( chat_entity, ChannelParticipantsSearch(key), offset, limit=200, hash=0)) print(key + ": " + str(participants.count)) |
Поясняю: мы взяли весь алфавит и перебрали буквы, пытаясь найти пользователей, в user_name которых она есть.
Смотрим, что получилось:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
A: 28068 B: 11188 C: 5721 D: 15950 E: 7522 F: 5280 G: 8812 H: 4002 I: 9233 J: 3642 K: 15177 L: 8264 M: 20343 N: 10546 O: 5903 P: 9001 Q: 1009 R: 9882 S: 22445 T: 9881 U: 2376 V: 12249 W: 2581 X: 1749 Y: 4324 Z: 4283 |
Как видно, иногда список результатов содержит меньше 10 тысяч, и тогда мы можем вытащить его полностью, иногда — больше, и тогда мы опять получим только первые 10 тысяч. Однако тест на группе со 190 тысячами юзеров позволил узнать данные о 140 тысячах, а это уже немало!
Наверняка существуют и другие способы поиграть с фильтрами и вытащить еще больше людей из чата. Пусть это будет вам домашним заданием.
Обратите внимание: этот способ работает намного дольше, и парсинг группы с несколькими десятками юзеров может занимать до нескольких десятков минут.
Сохранять результаты я рекомендую не в текстовый файл, а в какую‑нибудь базу данных, например SQLite:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
def add_users_in_base(bd_name, users): sqlite_connection = sqlite3.connect(bd_name) cursor = sqlite_connection.cursor() for user in users: sqlite_insert_query = "INSERT INTO users (id, deleted, bot, bot_chat_history ..... phone) VALUES (?,?,?,?,?,?,?,?) " data_tuple = ( user.id, user.deleted, user.bot, user.bot_chat_history, .... user.phone) try: cursor.execute(sqlite_insert_query, data_tuple) except sqlite3.Error as er: pass sqlite_connection.commit() cursor.close() sqlite_connection.close() |
Так сразу отсеиваются дубликаты, и потом будет намного удобнее работать с полученными данными: искать, сортировать, конвертировать.
Заключение
Итак, я вам показал, как извлечь из чата информацию о 10 тысячах его участников, а с применением фильтров — гораздо больше. Немного поэкспериментировав, вы сможете написать скрипты, которые соберут нужную вам информацию в удобном виде.
Если вдруг знаете еще какие‑то интересные методы по этой теме, не забудьте поделиться с нами в комментах!
РЕКОМЕНДУЕМ:




А слабо нормальный код скинуть, а не вот это частями?
Какой тебе код полностью, чего? Статью то прочитай! Ум
гении вы пацаны